
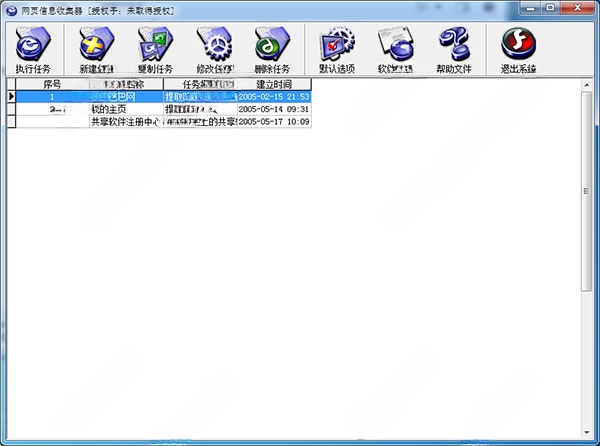
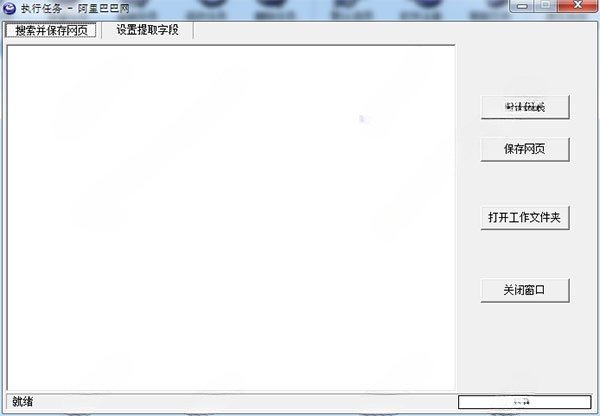
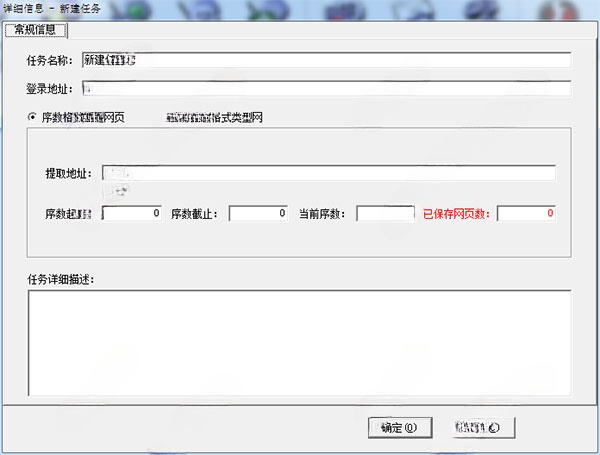
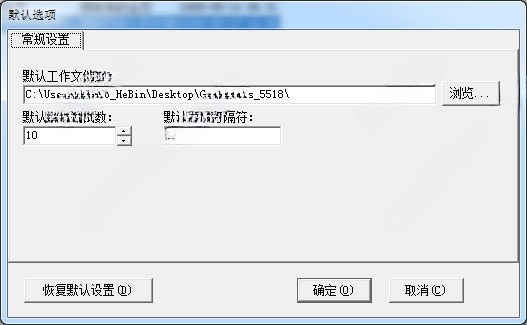
网页信息收集器
v1.0大小:1.04 M更新:2024/01/18
类别:网页辅助系统:WinXP, Win7, Win8, Win10, WinAll
分类分类
大小:1.04 M更新:2024/01/18
类别:网页辅助系统:WinXP, Win7, Win8, Win10, WinAll
Wappalyze插件网页辅助6.83 Mv6.10.15
详情淘客助手插件网页辅助296Kv9.0.0.2
详情1password chrome插件网页辅助6.16 Mv2.15.1
详情易大师网络工具箱网页辅助1.27 Mv2018.12.18
详情行云海网站监控软件网页辅助180Kv1.1.0.1
详情有道网页翻译2.0(chrome有道网页翻译插件)网页辅助17Kv
详情5118站长工具箱Chrome插件网页辅助532Kv2.0.4
详情listen1插件版网页辅助744Kv2.31.0
详情postman软件网页辅助143.14 Mv9.25.2
详情tampermonkey油猴脚本网页辅助1.45 Mv4.19.0
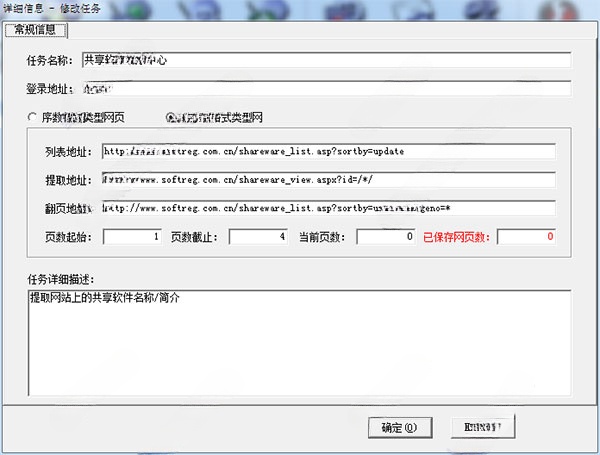
详情网页信息收集器网页辅助1.04 Mv1.0
详情悟空淘客助手网页辅助11.25 Mv2.0.5.208
详情global speed插件网页辅助403Kv
详情Web Maker最新版网页辅助2.47 Mv2.8
详情Webpage Screenshot chrome(网页快速截图编辑插件)网页辅助635Kv2.1.10
详情CherGet网页辅助2.84 Mv3.3
详情InternetSpeedTracker(chrome网速测试插件)网页辅助587Kv12.7
详情chrome flash control网页辅助93Kv6.13.0
详情lightshot(截图工具)插件网页辅助367Kv6.1.7
详情Unmask Password(chrome密码查看插件)网页辅助30Kv1.8
详情高效网页截图编辑插件(chrome网页截图编辑器)网页辅助721Kv9.1
详情NoFollow插件网页辅助58Kv3.5.0
详情ghostery插件网页辅助8.45 Mv8.12.4
详情Office Online插件网页辅助698Kv1.5.2
详情Responsive Web Design Tester响应式网页测试工具网页辅助768Kv1.0.24
详情resolution test插件网页辅助120Kv2.3
详情PicMonkey网页图片抓取插件网页辅助13Kv1.5
详情Multi highlight网页辅助53Kv1.20
详情HTTP间谍网页辅助145Kv2.0.44
详情cssviewer chrome网页辅助279Kv1.7
详情Ripple Emulator移动环境模拟器网页辅助4.54 Mv0.9.15
详情Nimbus Screensho网页截屏录屏插件网页辅助37.17 Mv8.4.6
详情Quick Color插件网页辅助97Kv1.0.1
详情Python Shell插件网页辅助891Kv4.0.7
详情Forest插件网页辅助13.5 Mv6.1.0
详情PP新标签网页辅助2.78 Mv6.0
详情chrome popup blocker网页辅助47Kv0.3.7
详情Overwatch Wallpapers HD网页辅助18.3 Mv0.1.5
详情Screen Shader网页辅助248Kv1.7.530
详情OurStickys网页注释笔记插件网页辅助167Kv0.1.92
详情点击查看更多
淘客助手插件网页辅助296Kv9.0.0.2
详情5118站长工具箱Chrome插件网页辅助532Kv2.0.4
详情Wappalyze插件网页辅助6.83 Mv6.10.15
详情cssviewer chrome网页辅助279Kv1.7
详情Unmask Password(chrome密码查看插件)网页辅助30Kv1.8
详情NoFollow插件网页辅助58Kv3.5.0
详情Screen Shader网页辅助248Kv1.7.530
详情Responsive Web Design Tester响应式网页测试工具网页辅助768Kv1.0.24
详情resolution test插件网页辅助120Kv2.3
详情1password chrome插件网页辅助6.16 Mv2.15.1
详情postman软件网页辅助143.14 Mv9.25.2
详情tampermonkey油猴脚本网页辅助1.45 Mv4.19.0
详情readability网页插件网页辅助318Kv3.0.15
详情高效网页截图编辑插件(chrome网页截图编辑器)网页辅助721Kv9.1
详情有道网页翻译2.0(chrome有道网页翻译插件)网页辅助17Kv
详情CherGet网页辅助2.84 Mv3.3
详情Office Online插件网页辅助698Kv1.5.2
详情Multi highlight网页辅助53Kv1.20
详情listen1插件版网页辅助744Kv2.31.0
详情Overwatch Wallpapers HD网页辅助18.3 Mv0.1.5
详情易大师网络工具箱网页辅助1.27 Mv2018.12.18
详情行云海网站监控软件网页辅助180Kv1.1.0.1
详情悟空淘客助手网页辅助11.25 Mv2.0.5.208
详情Web Maker最新版网页辅助2.47 Mv2.8
详情lightshot(截图工具)插件网页辅助367Kv6.1.7
详情ghostery插件网页辅助8.45 Mv8.12.4
详情chrome popup blocker网页辅助47Kv0.3.7
详情Open SEO Stats插件网页辅助729Kv9.6.0
详情Linkman书签管理工具网页辅助6.86 Mv8.9.9
详情牛津词典查询插件网页辅助12.82 Mv2.2.10
详情global speed插件网页辅助403Kv
详情Webpage Screenshot chrome(网页快速截图编辑插件)网页辅助635Kv2.1.10
详情PP新标签网页辅助2.78 Mv6.0
详情Save as PDF插件网页辅助61Kv1.11
详情InternetSpeedTracker(chrome网速测试插件)网页辅助587Kv12.7
详情Ripple Emulator移动环境模拟器网页辅助4.54 Mv0.9.15
详情Forest插件网页辅助13.5 Mv6.1.0
详情OurStickys网页注释笔记插件网页辅助167Kv0.1.92
详情Video Downloader GetThemAll网页辅助1.06 Mv30.0.2
详情PHP Console插件网页辅助47Kv3.0.21
详情点击查看更多
Wappalyze插件网页辅助6.83 Mv6.10.15
详情淘客助手插件网页辅助296Kv9.0.0.2
详情1password chrome插件网页辅助6.16 Mv2.15.1
详情易大师网络工具箱网页辅助1.27 Mv2018.12.18
详情行云海网站监控软件网页辅助180Kv1.1.0.1
详情有道网页翻译2.0(chrome有道网页翻译插件)网页辅助17Kv
详情5118站长工具箱Chrome插件网页辅助532Kv2.0.4
详情listen1插件版网页辅助744Kv2.31.0
详情postman软件网页辅助143.14 Mv9.25.2
详情tampermonkey油猴脚本网页辅助1.45 Mv4.19.0
详情网页信息收集器网页辅助1.04 Mv1.0
详情悟空淘客助手网页辅助11.25 Mv2.0.5.208
详情global speed插件网页辅助403Kv
详情Web Maker最新版网页辅助2.47 Mv2.8
详情Webpage Screenshot chrome(网页快速截图编辑插件)网页辅助635Kv2.1.10
详情CherGet网页辅助2.84 Mv3.3
详情InternetSpeedTracker(chrome网速测试插件)网页辅助587Kv12.7
详情chrome flash control网页辅助93Kv6.13.0
详情lightshot(截图工具)插件网页辅助367Kv6.1.7
详情Unmask Password(chrome密码查看插件)网页辅助30Kv1.8
详情高效网页截图编辑插件(chrome网页截图编辑器)网页辅助721Kv9.1
详情NoFollow插件网页辅助58Kv3.5.0
详情ghostery插件网页辅助8.45 Mv8.12.4
详情Office Online插件网页辅助698Kv1.5.2
详情Responsive Web Design Tester响应式网页测试工具网页辅助768Kv1.0.24
详情resolution test插件网页辅助120Kv2.3
详情PicMonkey网页图片抓取插件网页辅助13Kv1.5
详情Multi highlight网页辅助53Kv1.20
详情HTTP间谍网页辅助145Kv2.0.44
详情cssviewer chrome网页辅助279Kv1.7
详情Ripple Emulator移动环境模拟器网页辅助4.54 Mv0.9.15
详情Nimbus Screensho网页截屏录屏插件网页辅助37.17 Mv8.4.6
详情Quick Color插件网页辅助97Kv1.0.1
详情Python Shell插件网页辅助891Kv4.0.7
详情Forest插件网页辅助13.5 Mv6.1.0
详情PP新标签网页辅助2.78 Mv6.0
详情chrome popup blocker网页辅助47Kv0.3.7
详情Overwatch Wallpapers HD网页辅助18.3 Mv0.1.5
详情Screen Shader网页辅助248Kv1.7.530
详情OurStickys网页注释笔记插件网页辅助167Kv0.1.92
详情点击查看更多
 TVBox电视盒子
TVBox电视盒子






















































