Python实现SQL Server数据库实现对象同步轻量级
2024-02-05 11:03作者:下载吧
缘由
日常工作中经常遇到类似的问题:把某个服务器上的某些指定的表同步到另外一台服务器。
类似需求用SSIS或者其他ETL工作很容易实现,比如用SSIS的话,就会会存在相当一部分反复的手工操作。
建源的数据库信息,目标的数据库信息,如果是多个表,需要一个一个地拉source和target,然后一个一个地mapping,然后运行实现数据同步。
然后很可能,这个workflow使用也就这么一次,就寿终正寝了,却一样要浪费时间去做这个ETL。
快速数据同步实现
于是在想,可不可能快速实现类似需求,尽最大程度减少重复的手工操作?类似基于命令行的方式,简单快捷,不需要太多的手动操作。
于是就有了本文,基于Python(目的是顺便熟悉一下Python的语法),快速实现SQL Server的数据库之间的数据同步操作,后面又稍微扩展了一下,可以实现不同服务器的数据库之间的表结构,表对应的数据,存储过程,函数,用户自定义类型表(user define table type)的同步
目前支持在两个SQL Server数据源之间:每次同步一张或者多张表/存储过程,也可以同步整个数据库的所有表/存储过程(以及表/存储过程依赖的其他数据库对象)。
支持sqlserver2012以上版本
需要考虑到一些基本的校验问题:在源服务器上,需要同步的对象是否存在,或者输入的对象是否存在于源服务器的数据库里。
在目标服务器上,对于表的同步:
1,表的存在依赖于schema,需要考虑到表的schema是否存在,如果不存在先在target库上创建表对应的schema
2,target表中是否有数据?如果有数据,是否以覆盖的方式执行
对于存储过程的同步:
1,类似于表,需要考虑存储过程的schema是否存在,如果不存在先在target库上创建表对应的schema
2,类似于表,arget数据库中是否已经存在对应的存储过程,是否以覆盖的方式执行
3,存储过程可能依赖于b表,某些函数,用户自定义表变量等等,同步存储过程的时候需要先同步依赖的对象,这一点比较复杂,实现过程中遇到在很多很多的坑
可能存在对象A依赖于对象B,对象B依赖于对象C……,这里有点递归的意思
这一点导致了重构大量的代码,一开始都是直来直去的同步,无法实现这个逻辑,切实体会到代码的“单一职责”原则
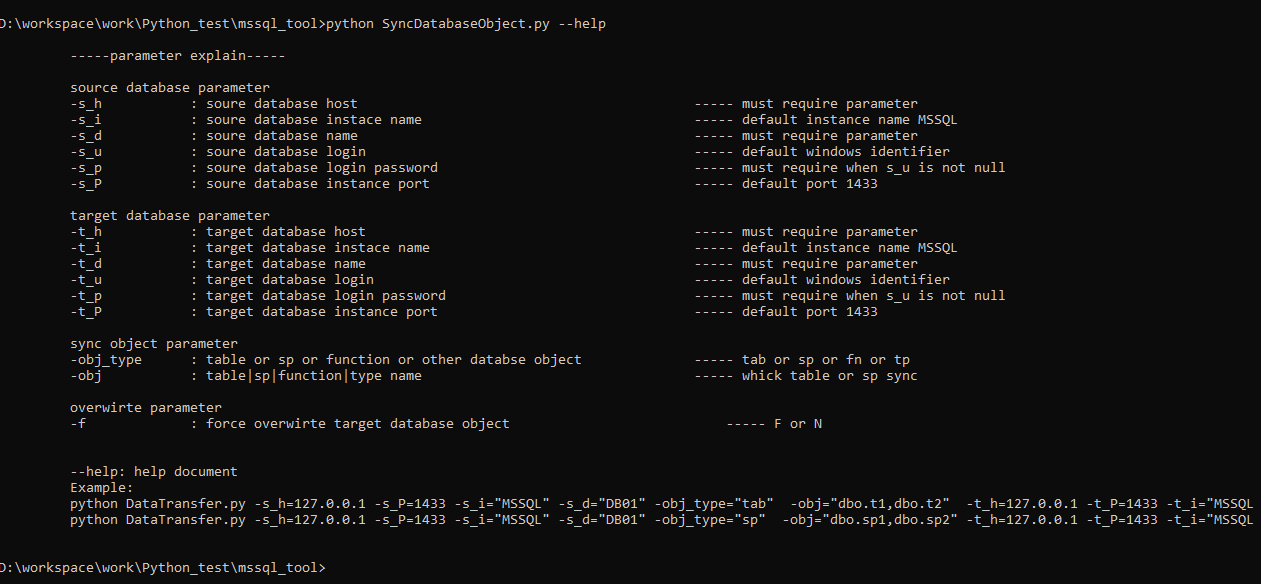
参数说明
参数说明如下,大的包括四类:
1,源服务器信息 (服务器地址,实例名,数据库名称,用户名,密码),没有用户名密码的情况下,使用windows身份认证模式
2,目标服务器信息(服务器地址,实例名,数据库名称,用户名,密码),没有用户名密码的情况下,使用windows身份认证模式
3,同步的对象类型以及对象
4,同步的对象在目标服务器上存在的情况下,是否强制覆盖
其实在同步数据的时候,也可以把需要同步的行数提取出来做参数,比较简单,这里暂时没有做。
比如需要快速搭建一个测试环境,需要同步所有的表结构和每个表的一部分数据即可。
表以及数据同步
表同步的原理是,创建目标表,遍历源数据的表,生成insert into values(***),(***),(***)格式的sql,然后插入目标数据库,这里大概步骤如下:
1,表依赖于schema,所以同步表之前先同步schema
2,强制覆盖的情况下,会drop掉目标表(如果存在的话),防止目标表与源表结构不一致,非强制覆盖的情况下,如果字段不一致,则抛出异常
3,同步表结构,包括字段,索引,约束等等,但是无法支持外键,刻意去掉了外键,想想为什么?因吹斯汀。
4,需要筛选出来非计算列字段,insert语句只能是非计算列字段(又导致重构了部分代码)
5,转义处理,在拼凑SQL的时候,需要进行转义处理,否则会导致SQL语句错误,目前处理了字符串中的’字符,二进制字段,时间字段的转义处理(最容易发生问题的地方)
6,鉴于insert into values(***),(***),(***)语法上允许的最大值是1000,因此每生成1000条数据,就同步一次
7,自增列的identity_insert 标识打开与关闭处理
使用如下参数,同步源数据库的三张表到目标数据库,因为这里是在本机命名实例下测试,因此实例名和端口号输入
执行同步的效果
说明:
1,如果输入obj_type=”tab” 且-obj=为None的情况下,会同步源数据库中的所有表。
2,这个效率取决于机器性能和网络传输,本机测试的话,每秒中可以提交3到4次,也就是每秒钟可以提交3000~4000行左右的数据。
已知的问题:
1,当表的索引为filter index的时候,无法生成包含where条件的索引创建语句,那个看起来蛋疼的表结构导出语句,暂时没时间改它。
2,暂时不支持其他少用的类型字段,比如地理空间字段什么的。
存储过程对象的同步
存储过程同步的原理是,在源数据库上生成创建存储过程的语句,然后写入目标库,这里大概步骤如下:
1,存储过程依赖于schema,所以同步存储过程之前先同步schema(同表)
2,同步的过程会检查依赖对象,如果依赖其他对象,暂停当前对象同步,先同步依赖对象
3,重复第二步骤,直至完成
4,对于存储过程的同步,如果是强制覆盖的话,强制覆盖仅仅对存储过程自己生效(删除&重建),对依赖对象并不生效,如果依赖对象不存在,就创建,否则不做任何事情
使用如下参数,同步源数据库的两个存储过程到目标数据库,因为这里是在本机命名实例下测试,因此实例名和端口号输入
说明:测试要同步的存储过程之一为[dbo].[sp_test01],它依赖于其他两个对象:dbo.table01和dbo.fn_test01()
create proc [dbo].[sp_test01] as begin set no count on; delete from dbo.table01 where id = 1000 select dbo.fn_test01() end