SQL开发知识:SQL Server索引的原理深入解析
2024-02-28 13:28作者:下载吧
1.聚集索引和非聚集索引
2.索引的结构
3.索引包含列和书签查找
前言
此文是我之前的笔记整理而来,以索引为入口进行探讨相关数据库知识(又做了修改以让人更好消化)。SQL Server接触不久的朋友可以只看以下蓝色字体字,简单有用节省时间;如果是数据库基础不错的朋友,可以全看,欢迎探讨。
索引的概念
索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法。
索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录可以快速找到你想要的信息,而不需要读完全书。在数据库中,数据库程序使用索引可以重啊到表中的数据,而不必扫描整个表。书中的目录是一个字词以及各字词所在的页码列表,数据库中的索引是表中的值以及各值存储位置的列表。
索引的利弊:查询执行的大部分开销是I/O,使用索引提高性能的一个主要目标是避免全表扫描,因为全表扫描需要从磁盘上读取表的每一个数据页,如果有索引指向数据值,则查询只需要读少数次的磁盘就行啦。所以合理的使用索引能加速数据的查询。但是索引并不总是提高系统的性能,带索引的表需要在数据库中占用更多的存储空间,同样用来增删数据的命令运行时间以及维护索引所需的处理时间会更长。所以我们要合理使用索引,及时更新去除次优索引。
1.聚集索引和非聚集索引
索引分为聚集索引和非聚集索引
1.1 聚集索引
表的数据是存储在数据页中(数据页的PageType标记为1),SqlServer一页是8k,存满一页就开辟下一页存储。如果表有聚集索引,那么一笔一笔物理数据就是按聚集索引字段的大小升/降排序存储在页中。当对聚集索引字段更新或中间插入/删除数据时,都会导致表数据移动(造成性能一定影响),因为它要保持升/降排序。
注意,主键只是默认是聚集索引,它也可以设置为非聚集索引,也可以在非主键字段上设置为聚集索引,全表只能有一个聚集索引。
一个优秀的聚集索引字段一般包含以下4个特性:
(A).自增长
总是在末尾增加记录,减少分页和索引碎片。
(B).不被更改
减少数据移动。
(C).唯一性
唯一性是任何索引最理想的特性,可以明确索引键值在排序中的位置。
更重要的是,索引键指唯一的话,它在每条记录里才可以正确指向源数据行RID。如果聚集索引键值不唯一,SqlServer就需要内部生成uniquifier 列组合当作聚集键保证“键值”唯一性;如果非聚集索引键值不唯一,就会增加RID列(聚集索引键或者堆表中的行指针)保证“键值”唯一性。
思考(可略过):索引“键值”在非叶子节点也有保证唯一性,原因应该是为了明确索引记录在非叶子节点中的位置。比如有个非聚集索引字段Name2,表中有很多Name2=’a’的记录,导致Name2=’a’在非叶子节点上有多条索引记录(节点),这时候再insert一笔Name2=‘a’的记录时,就可以根据非叶子节点的RID和新增记录的RID很快确定要insert到哪个索引记录(节点)上,如果没有非叶子节点的RID,那得遍历到所有Name2=’a’的叶子节点才能确定位置。另外,当我们select * from Table1 where Name2<=’a’时,返回的数据是按非聚集索引Name2和RID排序的,很好理解返回的数据就是按这边索引存储的顺序排序的。这是这条sql查询时有用到Name2索引的结果,如果数据库查询计划因“临界点”问题选择直接表数据扫描,那返回的数据默认就是按表数据的顺序排序的。
为了“键值”唯一性,对于聚集索引,uniquifier 列只在索引值重复时增加。对于非聚集索引,如果创建索引时没定义唯一,RID会在所有记录增加,就算索引值是唯一的;如果创建索引时定义唯一,RID只在叶子层增加,用于查找源数据行,即书签查找操作。
(D).字段长度小
聚集索引键长度越小,一页索引页就可以容纳更多索引记录,进而减少索引B树结构的深度。例如,一个百万记录的表有一个int聚集索引,可能只需要3层的B树结构。如果把聚集索引定义在更宽的列(比如uniqueidentifier列需要16 字节),那么索引的深度会增加到4层。任何聚集索引查找需要4个I/O操作(确切的说是4个逻辑读),原先只要3个I/O操作。
同样,非聚集索引里会包含聚集索引键值,聚集索引键长度越小非聚集索引记录也就越小,一页索引页就可以容纳更多索引记录。
1.2 非聚集索引
也是存储在页中(PageType标记为2的页,叫索引页)。比如表T建立了一个非聚集索引Index_A,那么表T有100条数据的话,那么索引Index_A也就有100条数据(准确的说是100条叶子节点数据,索引是B树结构,如果树的高度大于0,那么就有根节点页或中间节点页数据,这时索引数据就超过100条),如果表T还有非聚集索引Index_B,那么Index_B也是至少100条数据,所以索引建越多开销越大。
更新索引字段、插入一条数据、删除一条数据都会造成索引的维护从而造成性能的一定影响。在不同情况下,性能影响是不同的。比如当你有一个聚集索引,插入的数据又都是在末尾,这样几乎是不会造成数据移动,影响较小;如果插入的数据在中间位置,一般会导致数据移动,而且可能产生分页和页碎片,影响就会稍大一点(如果插入到的中间页有足够的剩余空间容纳插入的数据,而且位置是在页末,也是不会造成数据移动)
2.索引的结构
都说SqlServer的索引是B树结构(这边假定你对B树结构有一定了解),那它到底长什么个模样呢,可以用Sql语句来查看它的逻辑呈现。
新建查询执行语法: DBCC IND(Test,OrderBo,-1) –其中Test库的OrderBo表有1万笔数据,有聚集索引Id主键字段
(不妨自己动手建个表,有聚集索引字段,插入1万表数据,然后执行这个语法看看,会收获很多,百闻不如一见)
执行结果:
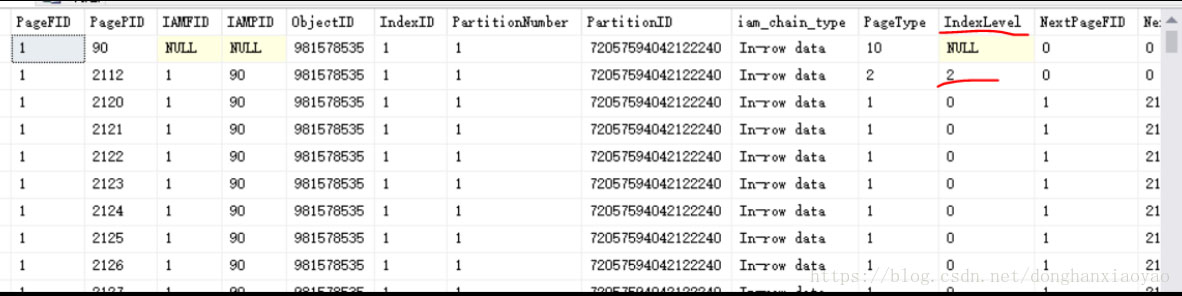
如上图,看到一个IndexLevel=2的索引页2112(这边它就是B树的根节点,IndexLevel最大的就是根节点,往下就是子级、子子级…只有一个根页作为B树结构的访问入口点),说明一定还有IndexLevel=1的索引页和IndexLevel=0的叶子页。由于这边是聚集索引,因此当IndexLevel=0的叶子页就是数据页,存储的是一笔一笔的物理数据。如上图也可以看到,IndexLevel=0的行的PageType等于1,就是代表数据页,上面1.1章节讲到聚集索引时,也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的叶子页,PageType是等于 2,仍然是索引页。
同样,我们用Sql命令DBCC PAGE看一看
— DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
–根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)
- 3.索引包含列和书签查找
- 前言
此文是我之前的笔记整理而来,以索引为入口进行探讨相关数据库知识(又做了修改以让人更好消化)。SQL Server接触不久的朋友可以只看以下蓝色字体字,简单有用节省时间;如果是数据库基础不错的朋友,可以全看,欢迎探讨。
索引的概念
索引的用途:我们对数据查询及处理速度已成为衡量应用系统成败的标准,而采用索引来加快数据处理速度通常是最普遍采用的优化方法。
索引是什么:数据库中的索引类似于一本书的目录,在一本书中使用目录可以快速找到你想要的信息,而不需要读完全书。在数据库中,数据库程序使用索引可以重啊到表中的数据,而不必扫描整个表。书中的目录是一个字词以及各字词所在的页码列表,数据库中的索引是表中的值以及各值存储位置的列表。
索引的利弊:查询执行的大部分开销是I/O,使用索引提高性能的一个主要目标是避免全表扫描,因为全表扫描需要从磁盘上读取表的每一个数据页,如果有索引指向数据值,则查询只需要读少数次的磁盘就行啦。所以合理的使用索引能加速数据的查询。但是索引并不总是提高系统的性能,带索引的表需要在数据库中占用更多的存储空间,同样用来增删数据的命令运行时间以及维护索引所需的处理时间会更长。所以我们要合理使用索引,及时更新去除次优索引。
1.聚集索引和非聚集索引
索引分为聚集索引和非聚集索引
1.1 聚集索引
表的数据是存储在数据页中(数据页的PageType标记为1),SqlServer一页是8k,存满一页就开辟下一页存储。如果表有聚集索引,那么一笔一笔物理数据就是按聚集索引字段的大小升/降排序存储在页中。当对聚集索引字段更新或中间插入/删除数据时,都会导致表数据移动(造成性能一定影响),因为它要保持升/降排序。
注意,主键只是默认是聚集索引,它也可以设置为非聚集索引,也可以在非主键字段上设置为聚集索引,全表只能有一个聚集索引。
一个优秀的聚集索引字段一般包含以下4个特性:
(A).自增长
总是在末尾增加记录,减少分页和索引碎片。
(B).不被更改
减少数据移动。
(C).唯一性
唯一性是任何索引最理想的特性,可以明确索引键值在排序中的位置。
更重要的是,索引键指唯一的话,它在每条记录里才可以正确指向源数据行RID。如果聚集索引键值不唯一,SqlServer就需要内部生成uniquifier 列组合当作聚集键保证“键值”唯一性;如果非聚集索引键值不唯一,就会增加RID列(聚集索引键或者堆表中的行指针)保证“键值”唯一性。
思考(可略过):索引“键值”在非叶子节点也有保证唯一性,原因应该是为了明确索引记录在非叶子节点中的位置。比如有个非聚集索引字段Name2,表中有很多Name2=’a’的记录,导致Name2=’a’在非叶子节点上有多条索引记录(节点),这时候再insert一笔Name2=‘a’的记录时,就可以根据非叶子节点的RID和新增记录的RID很快确定要insert到哪个索引记录(节点)上,如果没有非叶子节点的RID,那得遍历到所有Name2=’a’的叶子节点才能确定位置。另外,当我们select * from Table1 where Name2<=’a’时,返回的数据是按非聚集索引Name2和RID排序的,很好理解返回的数据就是按这边索引存储的顺序排序的。这是这条sql查询时有用到Name2索引的结果,如果数据库查询计划因“临界点”问题选择直接表数据扫描,那返回的数据默认就是按表数据的顺序排序的。
为了“键值”唯一性,对于聚集索引,uniquifier 列只在索引值重复时增加。对于非聚集索引,如果创建索引时没定义唯一,RID会在所有记录增加,就算索引值是唯一的;如果创建索引时定义唯一,RID只在叶子层增加,用于查找源数据行,即书签查找操作。
(D).字段长度小
聚集索引键长度越小,一页索引页就可以容纳更多索引记录,进而减少索引B树结构的深度。例如,一个百万记录的表有一个int聚集索引,可能只需要3层的B树结构。如果把聚集索引定义在更宽的列(比如uniqueidentifier列需要16 字节),那么索引的深度会增加到4层。任何聚集索引查找需要4个I/O操作(确切的说是4个逻辑读),原先只要3个I/O操作。
同样,非聚集索引里会包含聚集索引键值,聚集索引键长度越小非聚集索引记录也就越小,一页索引页就可以容纳更多索引记录。
1.2 非聚集索引
也是存储在页中(PageType标记为2的页,叫索引页)。比如表T建立了一个非聚集索引Index_A,那么表T有100条数据的话,那么索引Index_A也就有100条数据(准确的说是100条叶子节点数据,索引是B树结构,如果树的高度大于0,那么就有根节点页或中间节点页数据,这时索引数据就超过100条),如果表T还有非聚集索引Index_B,那么Index_B也是至少100条数据,所以索引建越多开销越大。
更新索引字段、插入一条数据、删除一条数据都会造成索引的维护从而造成性能的一定影响。在不同情况下,性能影响是不同的。比如当你有一个聚集索引,插入的数据又都是在末尾,这样几乎是不会造成数据移动,影响较小;如果插入的数据在中间位置,一般会导致数据移动,而且可能产生分页和页碎片,影响就会稍大一点(如果插入到的中间页有足够的剩余空间容纳插入的数据,而且位置是在页末,也是不会造成数据移动)
2.索引的结构
都说SqlServer的索引是B树结构(这边假定你对B树结构有一定了解),那它到底长什么个模样呢,可以用Sql语句来查看它的逻辑呈现。
新建查询执行语法: DBCC IND(Test,OrderBo,-1) –其中Test库的OrderBo表有1万笔数据,有聚集索引Id主键字段
(不妨自己动手建个表,有聚集索引字段,插入1万表数据,然后执行这个语法看看,会收获很多,百闻不如一见)
执行结果:
如上图,看到一个IndexLevel=2的索引页2112(这边它就是B树的根节点,IndexLevel最大的就是根节点,往下就是子级、子子级…只有一个根页作为B树结构的访问入口点),说明一定还有IndexLevel=1的索引页和IndexLevel=0的叶子页。由于这边是聚集索引,因此当IndexLevel=0的叶子页就是数据页,存储的是一笔一笔的物理数据。如上图也可以看到,IndexLevel=0的行的PageType等于1,就是代表数据页,上面1.1章节讲到聚集索引时,也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的叶子页,PageType是等于 2,仍然是索引页。
同样,我们用Sql命令DBCC PAGE看一看
— DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
–根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)